这是我自学 MIT6.033 课程的第二部分:Networking 的笔记。
该课程共分为 4 部分:Operating Systems、Networking、Distributed Systems、Security课程详细介绍可以查阅:https://blog.miigon.net/posts/mit6033-computer-system-design/
笔记为学习过程中随笔记录以及思考,未经整理,所以可能会比较零散。
这一部分 Lecture 讲的内容,与计算机网络有一定重合,这里笔记偏向于在系统设计中需要考虑的概念,而至于具体的协议、网络通信的具体细节等,即使在 lecture 视频中提到了,也不会记录到笔记中。这一部分细节可以通过计算机网络课程学习。
LEC7 Intro to networking and layering
How do modules of a system communicate if they’re on separate machines? 网络。 网络是一个系统的重要部分,许多系统的错误来源都来自于网络错误。
不同机器上模块的通信 - 网络
网络:包含 end point,以及将这些 end point 连接在一起的中间节点 switch 以及边 link 形成的图 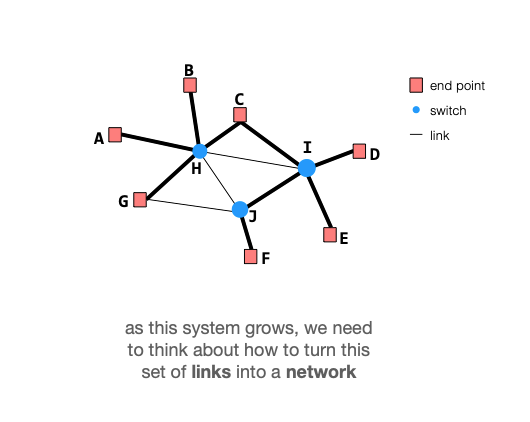
随着系统增长,需要考虑如何将这些链接转化成一个「网络」
网络层级:
- link:两个直接相连的节点之间的通信
- 例子:以太网、蓝牙、802.11
- network: 多个 link 以及节点形成的网络
- 这一层需要考虑的问题:节点的命名naming、寻址addressing、路由routing
- 不仅是简单的图最短路问题,网络需要考虑节点的加入、离开,网络不会有一个中心的权威者来规划一切
- 节点需要完全靠自己,去知道自己的邻居、以及离自己较远的网络的其他地方的情况(分布式的系统)
- transport: 共享网络;保证可靠(或不保证)
- 这一层所面对的问题:如何公平地在节点之间共享网络,如何应对网络的不可靠性
- application: 实际产生网络流量
因特网历史与演变
这部分的配图:https://web.mit.edu/6.033/www/lec/s07-partial.pdf
早期因特网,Pre-1993
- 1970s:ARPAnet,起初很小,使用 hosts.txt 对节点进行命名(难以scale,但是在早期节点数少的情况下足够),使用「距离向量路由distance-vector routing」,使用滑动窗口收发。
- 1978:灵活性与分层结构出现,常见的模型:
- 应用层:产生网络流量
- 运输层:可靠运输,带宽共享
- 网络层-IP:寻址/路由(图上寻径)
- 链路层:相邻节点间的点到点链路
- 理想状态下,分层架构使得我们可以方便地更换协议,而不影响其他层
- 1983:TCP可靠传输。应用不再需要自己实现可靠传输。
增长 => 改变
- 1978-79: 链路状态路由 link-state routing,EGP(分层的路由方式),更可扩张(scalable)的路由方式。
- 1982:DNS:更可扩张的命名方式。分布式管理带来的增长(网站管理者可以自己管理自己的DNS 服务器,可自己添加新的主机与命名,即子域名)
增长 => 问题
what can go wrong when things get big?
- 80年代中期:拥塞倒塌 congestion collapse。网络被无用数据包/重传包堵塞。TCP加入拥塞控制机制。
- 90年代早期:策略路由policy routing。互联网开始商业化,互联网的一些组成部分(如大学、政府机构、大公司)并不想为商业流量提供传输。策略路由(BGP)提供了解决方法。
- 寻址。按照不同大小的块来分配地址。(A类、B类、C类)=> CIDR 协议
英特网,Post-1993
1993: 商业化。改变停止。“新技术基本上都是由于恐惧或者贪婪的原因才被部署的”
现在所需要面临的问题
- DDoS:难以避免,互联网设计之初并没有考虑责任性accountability
- 安全:DNS、BGP等完全没有安全措施,可以说谎。
- 移动性:根本没人会想到这一点
- 地址空间枯竭:IPv4 -> IPv6
- 拥塞控制:也许需要改变
反复出现的主题
- 分层 layering 与分级 hierarchy
- 可扩张性 scalability:如果确保模块性 modularity 是 6.033 第一部分的主题,则可扩张性则是第二部分的主题。
- 效率/性能:性能需求影响网络的设计
- 应用的多样性:有的关心吞吐(如下载)、有的关心延迟(如游戏),有的都在乎,有的需要可靠性,有的不需要……等等。我们需要构建一个可以支撑所有这些需求的网络
- 端到端争议:互联网的什么功能应该由那些部分来实现?(端点?交换机?etc.)
LEC8 Routing
在因特网或任何网络上的routing,以及think about how well they scale.
路由表routing table
- 目标:让每个交换机知道,任何两节点之间的最低开销(minimum-cost)路径
- cost:可以是任意指标或多指标的综合,如延迟、吞吐、拥塞、流量价格。可动态变化。
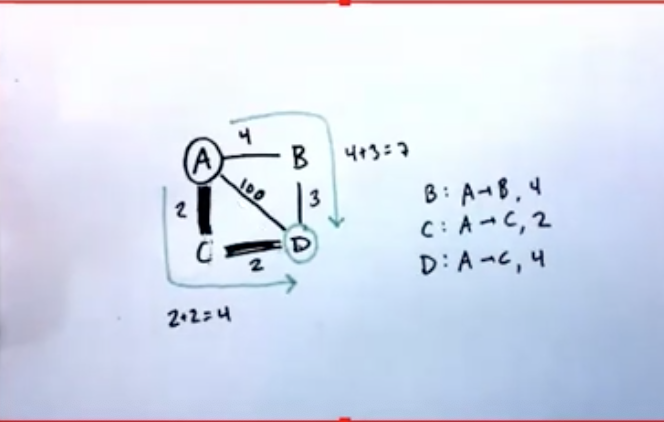
- 路径path:整个从起点A到终点D的完整路径
路由route:当前点A到终点D的路径中,作出的一次hop称为一个route(在A到D的例子中,就是第一步A->C的这个hop,即route只关心当前节点以及下一节点,不关心整条链路)
- routing table:包含了指引当前packet前往下个节点的映射表(一般为IP段映射到该router的某个interface,即相邻链路节点)
路由协议routing protocol
中心化的路由表构建协议无法scale,只考虑分布式,即节点独立获取自己所需要的信息,然后独自构建它们自己的路由表。
- Goal: For every node X, after the routing protocol is run, X’s routing table should contain a minimum-cost route to every other reachable node.
- 节点通过 HELLO 协议探测邻居节点的存在(类似TCP三次握手),该协议不断执行(以检测failure)
- 节点通过某种advertisement协议,从其他节点提供的信息探测到整个网络的所有其他可达节点
- 此时每个节点都有一份完整的AS内的网络拓扑结构,可以使用如最短路算法等来计算从自己到每个节点的最短路,并生成路由表(什么IP段应该向什么端口发送)。
因为网络可能变化,节点可以加入或离开网络,链路开销也可能随时变化,所以这个过程需要不断运行,以保证节点的路由表反映了最新的网络状况。
link state routing (eg. OSPF)
节点A在探测到自己的所有邻居后,将尝试使用flooding洪流式公告,尝试将自己的邻居信息告诉网络中的所有其他节点。 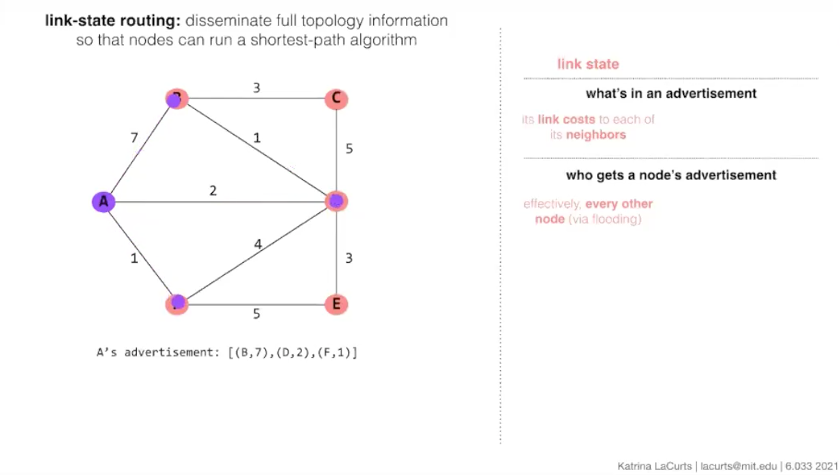 每一个节点收到A的公告后,都会进一步地转发给自己的邻居节点,所以称作“flooding”,洪水一样地在网络里不断转发(like 广度优先搜索)。
每一个节点收到A的公告后,都会进一步地转发给自己的邻居节点,所以称作“flooding”,洪水一样地在网络里不断转发(like 广度优先搜索)。
等到所有的节点都进行过flooding后,所有节点都知道了所有其他节点的邻居,也就构建出来网络的拓扑结构了。可以进一步在网络上跑最短路算法。
flooding的一个副作用是,由于有充分的冗余redundancy,现实中advertisement丢失的可能性很小。但这些冗余也带来了更大的overhead开销。(这是link state routing 无法 scale 到整个因特网级别的主要原因)
distance vector routing (eg. RIP)
在 link state routing 中,节点计算出了完整的最短路径。但实际上生成路由表,只需要知道最短路径上的下一跳(route路由,路牌/指向)即可。distance vector routing 利用了这一点。
节点A在探测到自己的所有邻居后,将自己的所有已知节点以及对应开销(包括邻居与非邻居)告诉自己的相邻节点(约等于把自己的路由表发送出去)(每次只发给所有邻居,不flood,邻居无需进一步转发这个信息)。
整合阶段:每一次一个节点收到相邻节点的adversitement,看是否能通过这个节点找到一条通向每一个目标节点dst的更好路径,若能,则更新自己的路由表:为dst采用这一节点作为新的路由(下一hop)。
多次运行后,每个节点就都能知道网络中要到达每个点的路由了(只知道路由,也就是最佳的下一跳是谁,而不知道整条链路)
由于不依赖flooding来传输信息,所以overhead开销更小。
问题:timing matters。每个节点发出公告的时机,尤其在链路失效发生时,会严重影响最终结果。最差情况下一个节点的断连,会导致关于这个节点的路由开销会在两个路由器之间来回广播累加直到达到infinity。(看LEC视频时间戳41:30到48:00)
由于failure发生时“累加到infinity”问题不可避免,以及failure的普遍性,一般infinity需要设置为较小的数字以减轻累加到infinity的影响,在实际网络中常常是16或32之类的小数字。这也就意味着,在使用该路由协议的网络中,最长的链路不能超过16或32(infinity),这是限制 distance vector routing scale 到整个因特网的主要因素。
what do we do
这两种算法都不能scale到因特网的量级,也都不支持策略路由policy routing。那么因特网上实际的路由是如何实现的?小网络内独立建立路由+BGP粘合小网络成为因特网。
LEC9 BGP
互联网的极速增长 => 重新设计路由协议以适应规模,以及实行策略路由(policy routing)。
[[IP数据包从出发到目的节点全过程 & 路由与路由表 & 自治网络 & BGP]]
如何应对在互联网上的scale问题
分级路由(routing hierarchy)
- 互联网被分割为许多自治系统(Autonomous Systems, AS)。自治系统可以是一个大学、一个运营商、政府分支等等。每个AS都有自己独特的ID。互联网目前共有上万个这样的AS。
- AS之内的路由以及AS与AS之间的路由采用不同的路由协议。
- 在每一个自治网络AS的边缘,有设备可以在这两种不同的协议之间相互“翻译”。
- AS之间使用的路由指向协议是BGP
path vector routing
- 和 distance vector routing 相似,但是advertisement中包含了整个完整路径。overhead增大,但仍然比link state routing要小。汇聚时间减小(由于整合的时候有完整路径,能避免routing loop,可以避免在出现节点故障时某些路由来回广播直到infinity的问题)
distance vector routing 和 link state routing 的折中。overhead开销介于两者之间
BGP 是一个 path vector routing 协议。
拓扑寻址(topological addressing)
- 即使在不同AS之间,BGP依然路由到IP地址(实际上是地址段)
- 为AS分配连续的地址段(CIDR表示法,192.168.1.0/24格式),使得BGP可以用地址段作为路由目的地,保持每个advertisement相对较小(相比为AS内的每一个IP地址都advertise一个路径而言)
policy routing
AS想要实现“策略路由”,交换机基于人类设置的策略进行决策。方式:选择性公告。只在能获得经济利益的前提下才对一个节点公告一条线路。 关于这个话题的更多阅读资料:https://web.mit.edu/6.033/www/papers/InterdomainRouting.pdf
(see LEC9 21:30)
常见的AS关系
- 客户/运营商:客户付费获得网络服务(home)
- peers:互相提供给对方自己路由表的子集,增加互联。互利行为。(比如电信和移动网的互联。早期互联网的peer互联比较匮乏,稳定性也比较差,所以游戏会有不同线路的服务器)
BGP
BGP 是一个应用层协议 application layer protocol。 BGP 策略一般由人设置,所以经常可以看到误配置导致的大规模中断(如2021年10月的 facebook outage)
BGP basically relies on the honor system(BGP并不安全,BGP spoofing,AS对 BGP 公告的绝对信任) (2008年巴基斯坦ISP公告伪造的Youtube线路导致世界Youtube断连)
LEC10 Reliable Transport and Congestion Control (TCP)
- 目标:提供可靠传输,防止拥塞
- 更大的问题:我们如何可 scale 地实现这个目的?如何将网络高效而又公平的共享?
基于滑动窗口的可靠传输
- 目标:接收程序能接收到一个完整的、无重复的有序字节流。即有序的每个packet包的一个拷贝。
- 为什么需要做?网络不可靠。包可能丢失,也可能乱序。
TCP:端到端协议,smart端系统,dumb交换机(交换机只负责在拥塞时进行丢包,而不会提供任何帮助)
(LEC接下来的内容是演示了TCP滑动窗口的工作示例以及拥塞控制,具体细节不展开,可参考计算机网络课程)
拥塞控制:通过控制滑动窗口大小,方式:AIMD(线性增加,倍数回退)
额外机制
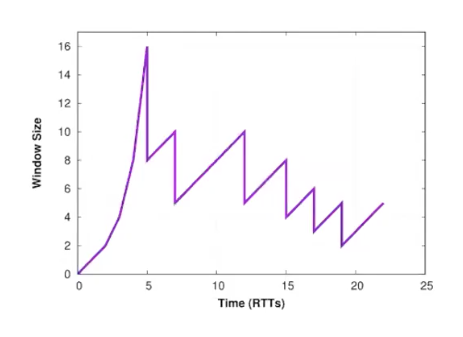
- slow start(实际上是快启动,启动阶段指数放大window size,直到出现丢包为止开始回退。相比一开始就跑大窗口来说是“slow start”)
- 快速重传/快速恢复(有时通过重复ACK可以直接推断某个包丢失,则可以直接开始重传而不需要等待超时)
回顾
- TCP 是巨大的成功,不需要对互联网的基础架构做任何更改。端点可自由参与使用,使得网络可以在大量用户之间分布式地共享。
- BUT: TCP 只能相应已经正在发生的拥塞。有更好的办法吗?
LEC11 In-network Resource Management
网络链路共享,but with 交换机的帮助 拥塞控制:需要一个cue作为backoff的信号,在TCP中这个信号是「丢包」。也就是TCP必须等到出现问题之后才会开始相应。
交换机中的队列如何决定何时丢包
丢尾DropTail
最基本的队列管理策略,如果包到达时队列已满,则丢弃;否则则将其加入队列。主动丢包概率p=(queue_full ? 1 : 0);
- 优点:简单
- 缺点:来源有可能会被「同步」(即同时检测到丢包,同时回退,导致链路从过载突然变成欠载,导致链路利用率下降)
RED(Random Early Drop,随机提前丢包)
主动队列管理(active queue management)方案,在队列未完全满之前就开始随机丢包,以提前给TCP发送「拥塞正在形成」的信号。主动丢包概率与一段时间内的平均队列长度正相关。
平均队列长度计算公式:q_avg = a*q_instant + (1-a)*q_avg ; 0 < a << 1(低通滤波,消除高频波动。q_instant是采样瞬间的队列长度,越往后的采样点贡献越大)
优点:
- 队列波动减小
- 由于拥塞而造成的丢包率变化更加平稳
- 数据流去同步(分散开始回退,避免同时回退) 可能的缺点:依然依赖丢包,源头依然需要重新传输。
ECN(Explicit Congestion Notification,显式拥塞通知)
与RED类似,但相比丢包,只在包头上做标记。发送者通过ACK包上的标记来检测拥塞。 ECN的有效施行,要求发送者对标记做出相应。
主动队列管理的问题
这些主动队列管理模式的一个问题是,相比被动拥塞控制,它们更加复杂。包含了许多与网络状态相关的需要设置的参数,而网络是不断变化的。这些参数如果设置不当,有时候会使得效果更差。
流量区分
将不同类型的流量放到不同的队列中,并在队列上做特殊处理。(流量调度)
流量调度
基于延迟的调度
多级优先级队列:不同优先级拥有单独的队列,只有高优先级的队列为空时才会开始发送低优先级的队列。(调度问题)
问题:大量的高优先级流量(如游戏流量)会 starve out 低优先级流量(如email)
基于带宽的调度
为每一个队列分配一定量的带宽
轮询、带权轮询(Weighted Round-robin)
轮流准许每个队列发送数据。带权轮询可以用于手动指定优先级(或者在按包轮询的实现中,可以使用权来将其转换为等数据量)。(细节略,LEC11 33:30)
缺点:如果需要实现按数据量分配的话,需要提前知道或者测量计算出某队列的平均包大小,才能生成适合的权用于确定每轮每个队列应该传输多少个包。
deficit round-robin赤字轮询
不同的队列可以积累“积分”用于下一轮的发送。
每一轮:
1
2
3
4
5
for each queue q:
q.credit += q.quantum // 每轮累积一定数量的积分
while q.credit >= size of next packet p: // 当积分足够发送下一个包时
q.credit -= size of p // 消耗积分
send p // 发送包
ps. 为每个队列加上最大令牌数量限制,就几乎是令牌桶算法了
好处:能实现限流以及几乎绝对公平的带宽分配,不需要提前知道平均包大小。且允许变化的包大小以及一部分的突发流量(靠积分累积)。
讨论
- 流量区分:是一个好主意吗?理论上是。但是:
- 难以确定合适的隔离粒度(按app?按flow?)
- 按app流量区分同时需要深层的包内容监测。昂贵、受加密通信阻挠。
- 按flow=状态过多
- 公平队列:「哪些流量重要,哪些流量不重要」应该由谁来决定?gov?isp?you?
这里涉及到了一个很有意思的话题叫做Net neutrality互联网中立性原则。
引用维基百科:要求互联网服务供应商及政府应平等处理所有互联网上的资料,不差别对待或依不同用户、内容、网站、平台、应用、接取设备类型或通信模式而差别收费。
其中有包含 dumb pipe 和 traffic shaping 的讨论,以及正反双方在“所有网络流量地位平等”这一问题上的立场,是有意思而且很有现实影响的一个话题。
Who should make decisions? Should we allow traffic to be prioritized at all?
LEC12 Application Layer, P2P Networks + CDNs
在因特网上分发内容content delivery。(最早期的互联网应用!)
文件分发的可选方案
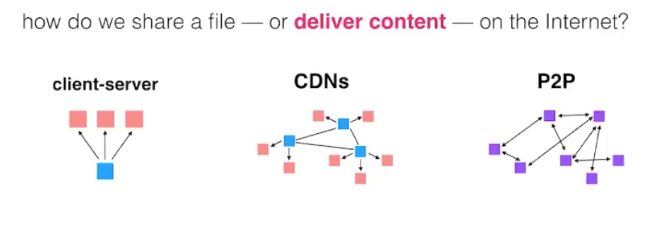
- Client/Server
- eg:FTP/HTTP
- 缺点:单点故障(single point of failure);不能 scale。
- CDNs
- 买多个服务器,放到客户附近降低延迟(分布式)
- 没有单点故障,更好的 scale
- P2P点对点网络
- 极端地分布式架构
- 理论上无限 scale (从上到下越来越分布式)
P2P 基础(以 BitTorrent 为例)
- .torrent 种子文件,包含关于文件的元信息(文件名,长度,构成文件的各部分的信息,tracker服务器的 URL)
- tracker服务器,知道所有与该文件传输有关的peer的信息的一个服务器
- 下载流程:联系tracker,tracker发送参与文件传输的所有peer。连接到这些peer,开始传输数据块。
- 一部分peer是做种者(seeder):已经有整个文件。可能是服务器或已经下好文件的下载者。
什么激励用户进行上传,而不是只下载?
- 高层面的:用户在上传给另一个用户之前不可以从对方下载数据。
peer想要互利关系:A必须有B要的块,反之亦然。 - 协议分成了轮:第n轮的时候,一些peer上传块给 X。在第n+1轮的时候,peer X 会发送块给第n轮中上传块最多的peer。
- peers如何开始整个流程(避免鸡蛋问题)?每个peer保留了一小部分可以免费分发的带宽。
问题1:tracker服务器可能成为「单点故障」
大多数的BT客户端现在是“无tracker”的。改用分布式哈希表Distributed Hash Table(DHT)。
问题2:网络容量
这样的网络的容量受限于用户的上传速度,而用户上传速度通常远小于用户的下载速度。
CDN 基础
CDN 可以帮助我们解决容量问题。一个公司拥有CDN网络,其他公司付费使用CDN将内容传输给用户。围绕世界设置上千服务器,用户通常从“最优”服务器下载(一般是距离它们很近的一个)
overlay network
问题:
- 在哪里设置这些服务器?
- 如何保持内容最新(6.033下一部分的话题)
- 如何将客户引导到“正确”的服务器?(eg. 利用DNS的indirection)
- 错误处理?如何将用户从故障的服务器引导到其他服务器