这是我自学 MIT6.S081 操作系统课程的 lab 代码笔记第十篇:Mmap。此 lab 大致耗时:6小时。
课程地址:https://pdos.csail.mit.edu/6.S081/2020/schedule.html
Lab 地址:https://pdos.csail.mit.edu/6.S081/2020/labs/mmap.html
我的代码地址:https://github.com/Miigon/my-xv6-labs-2020/tree/mmap
Commits: https://github.com/Miigon/my-xv6-labs-2020/commits/mmap本文中代码注释是编写博客的时候加入的,原仓库中的代码可能缺乏注释或代码不完全相同。
Lab 10: mmap (hard)
实现 *nix 系统调用 mmap 的简单版:支持将文件映射到一片用户虚拟内存区域内,并且支持将对其的修改写回磁盘。
这里涉及的操作系统基本概念是「虚存」,mmap 指令除了可以用来将文件映射到内存上,还可以用来将创建的进程间共享内存映射到当前进程的地址空间内。本 lab 只需实现前一功能即可。
代码实现
首先需要在用户的地址空间内,找到一片空闲的区域,用于映射 mmap 页。
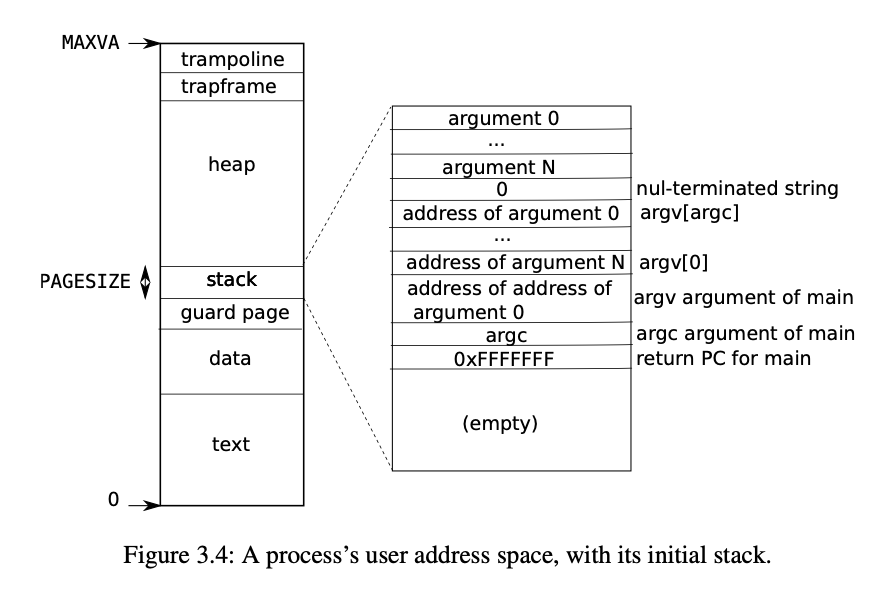
查阅 the xv6 book,可以看到 xv6 对用户的地址空间的分配中,heap 的范围一直从 stack 到 trapframe。由于进程本身所使用的内存空间是从低地址往高地址生长的(sbrk 调用)。
为了尽量使得 map 的文件使用的地址空间不要和进程所使用的地址空间产生冲突,我们选择将 mmap 映射进来的文件 map 到尽可能高的位置,也就是刚好在 trapframe 下面。并且若有多个 mmap 的文件,则向下生长。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// kernel/memlayout.h
// map the trampoline page to the highest address,
// in both user and kernel space.
#define TRAMPOLINE (MAXVA - PGSIZE)
// map kernel stacks beneath the trampoline,
// each surrounded by invalid guard pages.
#define KSTACK(p) (TRAMPOLINE - ((p)+1)* 2*PGSIZE)
// User memory layout.
// Address zero first:
// text
// original data and bss
// fixed-size stack
// expandable heap
// ...
// mmapped files
// TRAPFRAME (p->trapframe, used by the trampoline)
// TRAMPOLINE (the same page as in the kernel)
#define TRAPFRAME (TRAMPOLINE - PGSIZE)
// MMAP 所能使用的最后一个页+1
#define MMAPEND TRAPFRAME
接下来定义 vma 结构体,其中包含了 mmap 映射的内存区域的各种必要信息,比如开始地址、大小、所映射文件、文件内偏移以及权限等。
并且在 proc 结构体末尾为每个进程加上 16 个 vma 空槽。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// kernel/proc.h
struct vma {
int valid;
uint64 vastart;
uint64 sz;
struct file *f;
int prot;
int flags;
uint64 offset;
};
#define NVMA 16
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
struct vma vmas[NVMA]; // virtual memory areas
};
实现 mmap 系统调用。函数原型请参考 man mmap。函数的功能是在进程的 16 个 vma 槽中,找到可用的空槽,并且顺便计算所有 vma 中使用到的最低的虚拟地址(作为新 vma 的结尾地址 vaend,开区间),然后将当前文件映射到该最低地址下面的位置(vastart = vaend - sz)。
最后记得使用 filedup(v->f);,将文件的引用计数增加一。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
// kernel/sysfile.c
uint64
sys_mmap(void)
{
uint64 addr, sz, offset;
int prot, flags, fd; struct file *f;
if(argaddr(0, &addr) < 0 || argaddr(1, &sz) < 0 || argint(2, &prot) < 0
|| argint(3, &flags) < 0 || argfd(4, &fd, &f) < 0 || argaddr(5, &offset) < 0 || sz == 0)
return -1;
if((!f->readable && (prot & (PROT_READ)))
|| (!f->writable && (prot & PROT_WRITE) && !(flags & MAP_PRIVATE)))
return -1;
sz = PGROUNDUP(sz);
struct proc *p = myproc();
struct vma *v = 0;
uint64 vaend = MMAPEND; // non-inclusive
// mmaptest never passed a non-zero addr argument.
// so addr here is ignored and a new unmapped va region is found to
// map the file
// our implementation maps file right below where the trapframe is,
// from high addresses to low addresses.
// Find a free vma, and calculate where to map the file along the way.
for(int i=0;i<NVMA;i++) {
struct vma *vv = &p->vmas[i];
if(vv->valid == 0) {
if(v == 0) {
v = &p->vmas[i];
// found free vma;
v->valid = 1;
}
} else if(vv->vastart < vaend) {
vaend = PGROUNDDOWN(vv->vastart);
}
}
if(v == 0){
panic("mmap: no free vma");
}
v->vastart = vaend - sz;
v->sz = sz;
v->prot = prot;
v->flags = flags;
v->f = f; // assume f->type == FD_INODE
v->offset = offset;
filedup(v->f);
return v->vastart;
}
映射之前,需要注意文件权限的问题,如果尝试将一个只读打开的文件映射为可写,并且开启了回盘(MAP_SHARED),则 mmap 应该失败。否则回盘的时候会出现回盘到一个只读文件的错误情况。
由于需要对映射的页实行懒加载,仅在访问到的时候才从磁盘中加载出来,这里采用和 lab5: Lazy Page Allocation 类似的方式实现。具体请参考 lab5 笔记。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// kernel/trap.c
void
usertrap(void)
{
int which_dev = 0;
// ......
} else if((which_dev = devintr()) != 0){
// ok
} else {
uint64 va = r_stval();
if((r_scause() == 13 || r_scause() == 15)){ // vma lazy allocation
if(!vmatrylazytouch(va)) {
goto unexpected_scause;
}
} else {
unexpected_scause:
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
}
// ......
usertrapret();
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
// kernel/sysfile.c
// find a vma using a virtual address inside that vma.
struct vma *findvma(struct proc *p, uint64 va) {
for(int i=0;i<NVMA;i++) {
struct vma *vv = &p->vmas[i];
if(vv->valid == 1 && va >= vv->vastart && va < vv->vastart + vv->sz) {
return vv;
}
}
return 0;
}
// finds out whether a page is previously lazy-allocated for a vma
// and needed to be touched before use.
// if so, touch it so it's mapped to an actual physical page and contains
// content of the mapped file.
int vmatrylazytouch(uint64 va) {
struct proc *p = myproc();
struct vma *v = findvma(p, va);
if(v == 0) {
return 0;
}
// printf("vma mapping: %p => %d\n", va, v->offset + PGROUNDDOWN(va - v->vastart));
// allocate physical page
void *pa = kalloc();
if(pa == 0) {
panic("vmalazytouch: kalloc");
}
memset(pa, 0, PGSIZE);
// read data from disk
begin_op();
ilock(v->f->ip);
readi(v->f->ip, 0, (uint64)pa, v->offset + PGROUNDDOWN(va - v->vastart), PGSIZE);
iunlock(v->f->ip);
end_op();
// set appropriate perms, then map it.
int perm = PTE_U;
if(v->prot & PROT_READ)
perm |= PTE_R;
if(v->prot & PROT_WRITE)
perm |= PTE_W;
if(v->prot & PROT_EXEC)
perm |= PTE_X;
if(mappages(p->pagetable, va, PGSIZE, (uint64)pa, PTE_R | PTE_W | PTE_U) < 0) {
panic("vmalazytouch: mappages");
}
return 1;
}
到这里应该可以通过 mmap 测试了,接下来实现 munmap 调用,将一个 vma 所分配的所有页释放,并在必要的情况下,将已经修改的页写回磁盘。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
// kernel/sysfile.c
uint64
sys_munmap(void)
{
uint64 addr, sz;
if(argaddr(0, &addr) < 0 || argaddr(1, &sz) < 0 || sz == 0)
return -1;
struct proc *p = myproc();
struct vma *v = findvma(p, addr);
if(v == 0) {
return -1;
}
if(addr > v->vastart && addr + sz < v->vastart + v->sz) {
// trying to "dig a hole" inside the memory range.
return -1;
}
uint64 addr_aligned = addr;
if(addr > v->vastart) {
addr_aligned = PGROUNDUP(addr);
}
int nunmap = sz - (addr_aligned-addr); // nbytes to unmap
if(nunmap < 0)
nunmap = 0;
vmaunmap(p->pagetable, addr_aligned, nunmap, v); // custom memory page unmap routine for mmapped pages.
if(addr <= v->vastart && addr + sz > v->vastart) { // unmap at the beginning
v->offset += addr + sz - v->vastart;
v->vastart = addr + sz;
}
v->sz -= sz;
if(v->sz <= 0) {
fileclose(v->f);
v->valid = 0;
}
return 0;
}
这里首先通过传入的地址找到对应的 vma 结构体(通过前面定义的 findvma 方法),然后检测了一下在 vma 区域中间“挖洞”释放的错误情况,计算出应该开始释放的内存地址以及应该释放的内存字节数量(由于页有可能不是完整释放,如果 addr 处于一个页的中间,则那个页的后半部分释放,但是前半部分不释放,此时该页整体不应该被释放)。
计算出来释放内存页的开始地址以及释放的个数后,调用自定义的 vmaunmap 方法(vm.c)对物理内存页进行释放,并在需要的时候将数据写回磁盘。将该方法独立出来并写到 vm.c 中的理由是方便调用 vm.c 中的 walk 方法。
在调用 vmaunmap 释放内存页之后,对 v->offset、v->vastart 以及 v->sz 作相应的修改,并在所有页释放完毕之后,关闭对文件的引用,并完全释放该 vma。
vmaunmap():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
// kernel/vm.c
#include "fcntl.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "file.h"
#include "proc.h"
// Remove n BYTES (not pages) of vma mappings starting from va. va must be
// page-aligned. The mappings NEED NOT exist.
// Also free the physical memory and write back vma data to disk if necessary.
void
vmaunmap(pagetable_t pagetable, uint64 va, uint64 nbytes, struct vma *v)
{
uint64 a;
pte_t *pte;
// printf("unmapping %d bytes from %p\n",nbytes, va);
// borrowed from "uvmunmap"
for(a = va; a < va + nbytes; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0)
continue;
if(PTE_FLAGS(*pte) == PTE_V)
panic("sys_munmap: not a leaf");
if(*pte & PTE_V){
uint64 pa = PTE2PA(*pte);
if((*pte & PTE_D) && (v->flags & MAP_SHARED)) { // dirty, need to write back to disk
begin_op();
ilock(v->f->ip);
uint64 aoff = a - v->vastart; // offset relative to the start of memory range
if(aoff < 0) { // if the first page is not a full 4k page
writei(v->f->ip, 0, pa + (-aoff), v->offset, PGSIZE + aoff);
} else if(aoff + PGSIZE > v->sz){ // if the last page is not a full 4k page
writei(v->f->ip, 0, pa, v->offset + aoff, v->sz - aoff);
} else { // full 4k pages
writei(v->f->ip, 0, pa, v->offset + aoff, PGSIZE);
}
iunlock(v->f->ip);
end_op();
}
kfree((void*)pa);
*pte = 0;
}
}
}
这里的实现大致上和 uvmunmap 相似,查找范围内的每一个页,检测其 dirty bit (D) 是否被设置,如果被设置,则代表该页被修改过,需要将其写回磁盘。注意不是每一个页都需要完整的写回,这里需要处理开头页不完整、结尾页不完整以及中间完整页的情况。
xv6中本身不带有 dirty bit 的宏定义,在 riscv.h 中手动补齐:
1
2
3
4
5
6
7
8
9
10
// kernel/riscv.h
#define PTE_V (1L << 0) // valid
#define PTE_R (1L << 1)
#define PTE_W (1L << 2)
#define PTE_X (1L << 3)
#define PTE_U (1L << 4) // 1 -> user can access
#define PTE_G (1L << 5) // global mapping
#define PTE_A (1L << 6) // accessed
#define PTE_D (1L << 7) // dirty
最后需要做的,是在 proc.c 中添加处理进程 vma 的各部分代码。
- 让 allocproc 初始化进程的时候,将 vma 槽都清空
- freeproc 释放进程时,调用 vmaunmap 将所有 vma 的内存都释放,并在需要的时候写回磁盘
- fork 时,拷贝父进程的所有 vma,但是不拷贝物理页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
// kernel/proc.c
static struct proc*
allocproc(void)
{
// ......
// Clear VMAs
for(int i=0;i<NVMA;i++) {
p->vmas[i].valid = 0;
}
return p;
}
// free a proc structure and the data hanging from it,
// including user pages.
// p->lock must be held.
static void
freeproc(struct proc *p)
{
if(p->trapframe)
kfree((void*)p->trapframe);
p->trapframe = 0;
for(int i = 0; i < NVMA; i++) {
struct vma *v = &p->vmas[i];
vmaunmap(p->pagetable, v->vastart, v->sz, v);
}
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
p->pagetable = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->chan = 0;
p->killed = 0;
p->xstate = 0;
p->state = UNUSED;
}
// Create a new process, copying the parent.
// Sets up child kernel stack to return as if from fork() system call.
int
fork(void)
{
// ......
// copy vmas created by mmap.
// actual memory page as well as pte will not be copied over.
for(i = 0; i < NVMA; i++) {
struct vma *v = &p->vmas[i];
if(v->valid) {
np->vmas[i] = *v;
filedup(v->f);
}
}
safestrcpy(np->name, p->name, sizeof(p->name));
pid = np->pid;
np->state = RUNNABLE;
release(&np->lock);
return pid;
}
由于 mmap 映射的页并不在 [0, p->sz) 范围内,所以其页表项在 fork 的时候并不会被拷贝。我们只拷贝了 vma 项到子进程,这样子进程尝试访问 mmap 页的时候,会重新触发懒加载,重新分配物理页以及建立映射。
执行结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ mmaptest
mmap_test starting
test mmap f
test mmap f: OK
test mmap private
test mmap private: OK
test mmap read-only
test mmap read-only: OK
test mmap read/write
test mmap read/write: OK
test mmap dirty
test mmap dirty: OK
test not-mapped unmap
test not-mapped unmap: OK
test mmap two files
test mmap two files: OK
mmap_test: ALL OK
fork_test starting
fork_test OK
mmaptest: all tests succeeded