这是我自学 MIT6.033 课程的第一部分:Operating Systems 的笔记。
该课程共分为 4 部分:Operating Systems、Networking、Distributed Systems、Security课程详细介绍可以查阅:https://blog.miigon.net/posts/mit6033-computer-system-design/
笔记为学习过程中随笔记录以及思考,未经整理,所以可能会比较零散。
LEC1 Enforced Modularity via Client/Server Organization
复杂度
复杂度使得构建系统变得困难。
使用模块化和抽象的方式,来解决复杂度。
- 模块化:模块化的系统更容易理解、管理、改变、改进
- 模块化减少了「命运共享」(fate-sharing)
- 抽象使我们可以不指定具体实现的情况下进行交互(隐藏细节)
- 好的抽象设计应当减少模块之间的连接(低耦合)
「强制实施(Enforced)」的模块性
- 「软模块化」并不足够(eg. 面向对象,但是运行在同一程序内,即错误或崩溃会在模块间传播)
- 一种强制实施模块化的方法是客户端/服务器模型(使得模块可以运行在物理隔离的机器上。或者多进程,此时模块化与错误隔离能力由操作系统提供。)
系统设计的其他目标
- 除了降低复杂度,我们可能还希望有:可伸缩性(scalability)、容错性(fault-tolerance)、安全性(security)、性能(performance)等。
- 好的模块化设计可以帮助我们实现这些特性。
- 难以全部得到,多个之间有取舍。
LEC2 Naming
对模块的「命名」使得模块之间可以互相交互。
使用命名的好处
- 方便检索
- 共享(多个用户访问同一个名称)
- 用户友好
- 寻径(eg.IP地址、域名)
- 隐藏具体细节(以及访问控制)
- Indirection(间接,系统可以更换一个名字所指向的具体对象,而不需改动或通知客户端)
命名的 scheme 体现了我们希望系统通过命名来得到什么功能。(addressing, indirection, etc)
Naming Schemes
- namespace: 所有可能的名称集合 names
- 所有可能的值集合 values
- 从 name -> values 的映射/查找算法(name resolution)
需要思考的问题:
- 名称的语法是什么?
- 名称是否含有内部结构?(例如IP地址、域名)
- 名称是全局名称还是依赖上下文的局部名称?
- 系统的那一部分有权利来做「将一个名称绑定到一个值」这件事?(eg. nameserver)
- 一个名称可以对应多个值吗?(负载均衡)
- 名字对应关系是否可以随时间而改变?
- 名称解析在哪里发生?
取舍:eg. 分布性、可伸缩性、委托(delegation)
Example: DNS
benefit(与上面的需要思考的问题对应):
- 用户友好
- 负载均衡(一个名称对应多个值)
- 单机多网站(一个值对应多个名称)
- 名字对应关系可以随时间而改变
bad design 1
初期,在每一台主机都维护了一份 hosts 映射表,当新的主机加入网络的时候,新主机向所有现有主机发送更新:
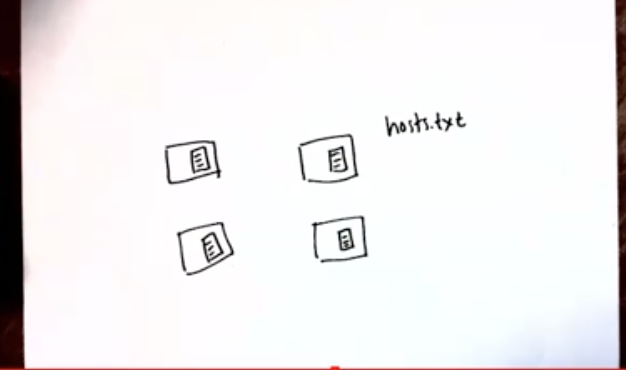
问题:难以 scale,一旦主机多起来,难以使所有机器上的映射表保持最新。 (也许还有 proofing attack 风险?)
bad design 2
用中央的服务器维护唯一的一份 hosts 映射表,每次其他主机访问域名时,都与中央服务器请求对应的 ip
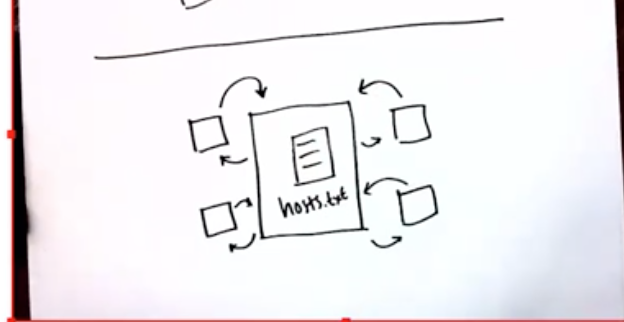
问题:解决了更新一致性问题,但是依然有 scale 问题,中央服务器需要处理成吨的请求
分布式的解决方法(DNS)
DNS 中,没有任何一个机器包含所有的映射关系。映射关系被分布在许多不同的机器上。
新问题:如何知道要访问的域名的映射关系存在哪一台机器上? 方案:DNS 名称的「结构本身」
思想:分布式(distributed)+分层架构(hierarchical)
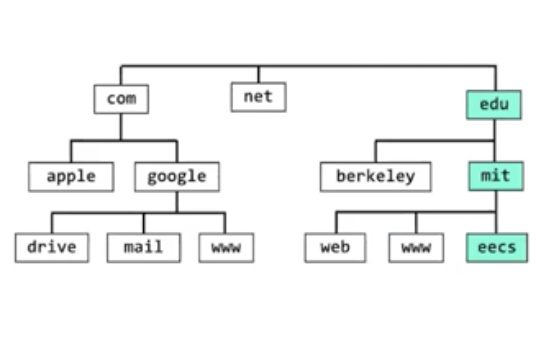
apple、google、mit 等自己管理自己的名称服务器(nameserver)。顶级域名 com、net、edu 管理的名称服务器只解析 apple.com、mit.edu 这种二级域名以及它们的名称服务器,而类似 eecs.mit.edu 这种三级域名的解析,由 mit.edu 自己的名称服务器提供。
请求解析的时候,向根服务器发出请求,请求一层层代理委托至最终的名称服务器,得到 ip 地址。
解析 blog.miigon.net 的过程:
1
2
3
4
5
6
7
8
9
10
root nameserver
-> NS of net is at 192.14.171.193
net nameserver (192.14.171.193)
-> NS of miigon.net is at 58.247.212.48
miigon.net nameserver (58.247.212.48)
-> blog.miigon.net A-record 185.199.108.153
blog.miigon.net is at 185.199.108.153
每一级向上一级/下一级请求的过程,如果由客户端完成,则为 iterative DNS,如果由每一级服务器代为完成,则为 recursive DNS。
root nameserver 的地址直接硬编码在机器中。
- 每一层解析,更接近最终的结果:这里体现了 delegation 委托,即根服务器不能直接给出查询结果,但是可以将请求委托给下一级名称服务器去完成。
类比:文件系统路径的分层结构 对比:对象存储服务,所有文件路径都只是扁平的键,没有分层结构 (体现的是另一种设计选择与取舍:低复杂度,高访问速度,但无法做目录遍历,也就是难以实现类似 ls 指令的功能)
依然有问题:
- 性能问题:解析需要许多请求,尤其是对根服务器
- 可靠性问题:名称服务器失效或(安全问题)被攻击
总结
- 「模块化」与「抽象」能降低复杂度。
- 「客户/服务器模型」使得我们可以通过将模块放在物理隔离的机器上,从而增加模块性
- 「命名」使得模块之间可以交互,同时提供了如间接性、用户友好等其他特性
- DNS 是一个很好的命名实例,同时展示了如分层(hierarchy)、可伸缩(scalability)、代理委托(delegation)、去中心化(decentralization)
REC3: DNS
- 递归(recursive)请求的好处是什么?
- 相比 iterative,简化客户端设计,只需要请求一个名称服务器,名称服务器代为完成整个请求过程。
- 容易实现 cache,如果请求的某一级服务器已经有完整记录,则可直接返回,而对于客户端来说是无感知的。
- DNS 分层架构的好处是什么?有什么缺点吗?
- 每一层只需管理/维护该层的映射关系,将工作量分摊到不同的层上的不同主机,避免了单主机处理所有请求
- 由每个名称服务器管理自己的域内的名称,无需担心更新时需要向某个中央服务器汇报导致难以 scale 的问题
- 依然不是完全分布式,依然有 single point of faliure(根服务器)
- 应该由谁控制 DNS 根服务器?
LEC3 Virtual Memory
操作系统
操作系统通过「虚拟化(Virtualization)」和「抽象(Abstraction)」,保证单机上的模块性
为了实现单机器上的模块性,操作系统需要实现的目标:
- 程序不应该可以访问和修改其他程序的内存(隔离) => virtual memory(今天话题)
- 程序之间应该可以互相通信(通信机制)
- 程序应该可以和其他程序共享 CPU
主要实现这些目标的手段:虚拟化 操作系统对硬件的不同部分进行虚拟化,让程序以为自己访问的是完整的物理硬件。
虚拟内存
让程序寻址整个地址空间,MMU 负责将虚拟地址转换为物理地址。
- Virtual Memory 也是一种 Naming Scheme,为我们提供了隐藏(隐藏其他程序的内存)、间接性(虚拟地址指向的实际地址可以随时改变,而不需要显式地告知程序)、访问控制(页表控制位,R/W)等特性。
Ideas
- 储存所有物理地址对应关系,使用整个虚拟地址作为 index
- 问题:表太大
- 页表:分页映射,虚拟地址前 p 位作为页 index,后 q 位作为页内偏移
- 体积小很多
- 虚拟内存是否真的能阻止程序访问其他程序的内存?(只有系统可以修改页表,+权限位,当程序尝试破坏这一模块性的时候,系统捕获exception,防止发生)
- 在这里会出现什么性能问题?(每次内存访问都有查表开销,缓解:TLB 快表作为 cache,潜在问题 consistency)
详细见S081。
多级页表(Hierarchical)
单级页表的设计依然需要使用许多空间,解决方法:多级页表,每一级存储指向下一级的地址,仅在使用到时分配。
tradeoff:
- 优点:更离散化的存储(利用零散内存页),占用更小空间
- 缺点:查询速度(多级查找而不是一级),更多的缺页异常
抽象(abstraction)
对于不可虚拟化的资源(磁盘、网络)(ps其实还是可以虚拟化的hhhhhh),系统提供抽象(系统调用),使得这些东西更加可移植。
LEC4 Bounded buffers and locks
操作系统(again)
操作系统通过「虚拟化(Virtualization)」和「抽象(Abstraction)」,保证单机上的模块性
为了实现单机器上的模块性,操作系统需要实现的目标:
- 程序不应该可以访问和修改其他程序的内存(隔离) => virtual memory
- 程序之间应该可以互相通信(通信机制) => 有界缓冲区与锁同步(今日话题)
- 程序应该可以和其他程序共享 CPU
Bounded buffers & locks (concurrency)
例子:unix pipe(consumer/producer)
考虑 consumer/producer 问题,如果可以用一个整数数值来描述资源剩余数量,比如剩余的 bounded buffers 空间,则可以用「信号量Semaphore」来同步。 如果资源可用条件较为复杂,无法使用整数描述,则应该使用「条件变量Condition variable」来同步(利用其较高的自由度,自定义唤醒条件) [[唤醒丢失问题 & 条件变量 vs 信号量 the lost wakeup problem & condition variable vs semaphore]]
本质:都是利用互斥锁同步。
Atomic actions
原子操作的粒度?
- 过粗:性能变低(根本原因是并行性受到了限制,体现为“锁竞争严重”)
- 过细:意外行为
tip:将锁的作用理解为「保护不变量」。在不变量被暂时破坏时保护数据结构,以不被外部察觉。在释放锁之前,operation 应该恢复该不变量。 [[锁的作用 Ways to think about what locks achieve]]
例子:文件系统中的锁
文件移动:
- 粗粒度锁:锁整个文件系统,问题:性能低,不能同时移动两个文件
- 细粒度锁:更好的性能,但是更难正确
- 例子:将 file1.txt 从 A 移动到 B,同时将 file2.txt 从 B 移动到 A (死锁,拿A锁等B锁,拿B锁等A锁)
- 例子解决方法:确保获取锁顺序,阻止环路形成。(例如强行要求先拿小inode号的目录的锁)
结论:一些系统中的锁问题以及锁设计,需要有全局观地去思考锁与锁之间的交互,而不能只考虑锁对局部代码的影响。
LEC5 Threads
操作系统(again again)
操作系统通过「虚拟化(Virtualization)」和「抽象(Abstraction)」,保证单机上的模块性
为了实现单机器上的模块性,操作系统需要实现的目标:
- 程序不应该可以访问和修改其他程序的内存(隔离) => virtual memory
- 程序之间应该可以互相通信(通信机制) => bounded buffers & locks
- 程序应该可以和其他程序共享 CPU => 虚拟化CPU(抢占式多线程 threads)
线程thread:一个虚拟的处理器(包装了一个程序的运行状态) 线程切换:将当前程序的运行状态换出,将另一个程序的运行状态换入(suspend/resume,或context switching)
- 线程需要包含的信息:所有的寄存器、所有的内存(利用页表切换实现)
- 何时挂起/恢复一个线程?(定期,yield())
线程主动放弃CPU:yield()
放弃当前线程的CPU执行权,保存当前线程的信息(栈、页表寄存器、callee-saved registers,不需要保存pc,因为在栈中的return address已经有),找到另一个可以运行的线程,并恢复新线程的运行状态(恢复栈指针、页表、callee-saved registers,ret指令返回到新线程之前yield后的位置)
这一部分在s081中有更详细展开:https://blog.miigon.net/posts/s081-lab7-multithreading/
在 bounded buffer 的 send 遇到缓冲区不足时,进程调用 yield 来主动放弃 CPU,但是进程可能在缓冲区出现空闲之前被再次调度唤醒,然后立刻又进入睡眠。

我们希望能够实现「yield,然后直到 buffer 中有空闲位置之前都不要再次唤醒该线程」(减小无意义唤醒)——操作系统提供条件变量机制来实现这一功能(condition variable)
条件变量(condition variable)
程序可以等待(wait)一个条件(condition)的发生,并且在该条件发生的时候收到通知。 另一进程可以在一个条件变为真的时候,使用 notify() 通知所有正在等待该条件的进程。
more on [[唤醒丢失问题 & 条件变量 vs 信号量 the lost wakeup problem & condition variable vs semaphore]] (https://blog.miigon.net/posts/the-lost-wakeup-problem-cond-var-vs-semaphore/)
问题:lost wakeup 唤醒丢失

进程 A 在完成 release(bb.lock) 之后,但是进入 wait(bb.has_space) 之前,另一个进程 B 可能会执行 receive,从而尝试唤醒正在等待 has_space 条件变量的进程。而此时唤醒的进程中不会包括进程 A。这时候进程 A 继续执行,然后才进入到 wait(bb.has_space) 中,而不会收到来自进程 B 的唤醒。
从而,进程 A “丢失” 了进程 B 发出的这一次唤醒。
唤醒丢失的后果轻者可能是使得进程 A 需要等待下一次条件为真时才能被唤醒,对于一些十分关键的条件变量,A 可能永远都不会再收到通知,从而陷入永久的沉睡。
解决方法:wait() 进入等待的同时,原子性地放弃锁。在被唤醒之后,原子性地重新获得锁,然后再从 wait 返回到用户代码。
即:
1
2
3
4
5
6
7
# pseudo-code
def wait(cond_var, mutex):
release(mutex)
currentthread.state = WAITING
currentthread.waiting_on = cond_var
yield_wait()
acquire(mutex)
注意 wait 整个操作必须是原子的,这一原子性可以通过给 wait 加一个额外的锁 tlock 实现。
问题:yield_wait 死锁
这里的 yield_wait 有一个很细微的死锁问题:
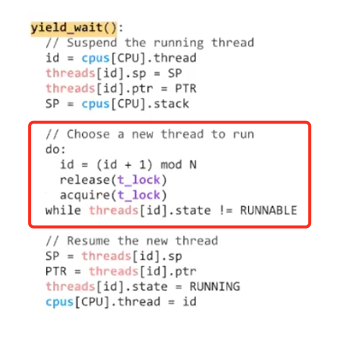
这里寻找可运行的线程的循环,由于 yield_wait 被调用时持有 t_lock,假设当所有其他线程都处于等待/不可运行状态,则该循环不会找到可运行的线程,并且更糟糕的是由于该循环执行时持有 t_lock,而其他 CPU 需要首先进行 yield 才能运行线程,而 yield 所要求的 t_lock 被 yield_wait 所在 CPU 持有着,则其他 CPU 无法推进任何线程的状态,该循环永远找不到可运行线程,整个系统进入死锁。这种情况在普通的 yield 中是不会出现的,因为普通的 yield 无论如何都至少会有切换前的原线程是 RUNNABLE 的,所以循环必然会终止(而对于 yield_wait 来说不是这样)。
这里是一个 CPU 持有 t_lock 去等待「有可运行线程出现」这一条件,而可运行的线程在出现前又需要获取 t_lock,造成环路等待。
解决方法比较简单,循环中需要间断性主动放弃 t_lock,破坏环路等待,使得其他 CPU 可以推进,从而使得「可运行线程出现」,解除死锁。
问题:两个 CPU 共用同一线程栈导致栈损坏
这里还有一个小细节,由于 yield_wait 此时使用的还是原线程的栈,此时放弃 t_lock 允许其他线程执行的时候,其他 CPU 可能会执行到该线程,而此时 yield_wait 的循环依然可能需要用到栈。从而导致有两个 CPU 使用同一个线程的栈,导致栈内容损坏。
这一情况比较稀有,但是依然可能出现,解决方法就是在进入 yield_wait 循环之前,将栈切换到其他地方,比如 CPU-specific 的栈,从而避免两个 CPU 共用一个线程栈。
如果线程不主动放弃 CPU 呢?抢占(preemption)。
使用时钟中断,定期中断 CPU 执行流,并强行调用 yield。
1
2
3
4
5
6
7
8
9
10
11
def timer_interrupt():
push PC
push ALL registers
yield() # will further save stack pointer,
# page table register and callee-saved registers
# since this is an interrupt, must restore all registers,
# instead of just the callee-saved ones.
pop ALL registers
pop pc
总结
- 「线程」虚拟化了 CPU,使得一个 CPU 可以在多个程序之间共享。
- 「条件变量」为线程提供了一个更高效的等待其他线程事件发生的 API
「抢占」使得一个进程能被中断并强制其放弃CPU,使得不需要依赖程序员主动调用 yield 来放弃 CPU(抢占式多线程以及协作式多线程)
- 操作系统中为用户程序提供模块化的三个不同方面:内存、通信、CPU;机制看起来不同,但都是虚拟化思想的应用(虚拟化环境,使得上层应用/模块可以运行在自己独立的环境中而与其他模块互不干扰)。
- 单机上的模块化(模块之间互相隔离)的保证,需要来自操作系统以及硬件的支持。
- 我们成功的利用操作系统的虚拟内存机制、通信机制、虚拟化CPU机制,保证了单机上的模块性。
LEC6 OS structure, Virtual Machines
另一种 virtualization 的应用:虚拟机
目标:在同一机器上同时运行多个系统
限制:兼容性。因为我们不希望需要修改内核的代码(否则称为半虚拟化)。
操作系统考虑的是如何将程序与程序之间隔离。虚拟机的任务是退后一步,也就是如何将操作系统与操作系统之间隔离。
内核中负责运行虚拟机的模块,称为 virtual machine monitor VMM (Linux kernel 中的实现为 KVM,windows 下为 hyperv)。
VMM 需要负责分配资源以及分发事件,这里重点考虑如何处理客户系统中执行的,需要与实际硬件交互的指令。
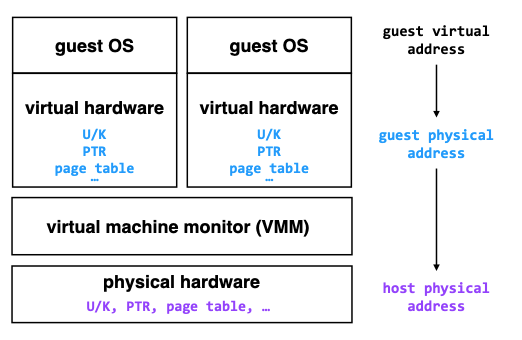
虚拟化 CPU
尝试方案1:模拟每一条客户系统执行的指令。问题:慢(内存比寄存器要慢100倍左右,仅仅是用内存去模拟寄存器这一步就会将性能降低两个数量级) 尝试方案2:用户系统直接在真实 CPU 上运行指令。问题:特权指令的处理
VMM 负责处理特权指令,当子系统执行特权指令的时候,会引发宿主系统的中断,并允许宿主系统处理这一特权指令。
方式:
- 通过将客户系统运行在用户态使得特权操作触发中断(trap-and-emulate)。但是有一些特权操作(如写入 U/K 位切换用户/内核态)本身就不会触发中断,需要修改客户系统或进行指令替换;
- 通过硬件提供的支持,如 Intel VT-x
虚拟化内存
- 方法1:将客户系统的页表内存设为只读,捕获每一个客户系统对页表的修改,并将其与宿主机的页表结合,生成一个合并页表,作为 CPU 实际使用的页表。
- 方法2:现代 CPU 含有对虚拟化的支持,CPU 同时知道客户系统以及宿主系统的页表的存在,并会在客户系统尝试访问内存时,依次查询两个页表。(拓展:嵌套虚拟化,CPU 会需要知道并查找 n 层页表)
内核架构
宏内核:
- Linux 内核,内核内部没有模块化与隔离,一个bug可以使整个系统崩溃。
- 由于复杂度,bug 容易出现 微内核:
- 将子系统——文件系统、设备驱动——运行为用户态程序。
- 更好的模块性,更少的 bug,bug 更不容易将整个系统带垮。
- 模块间接口设计更复杂,模块间通信性能可能受影响。
性能
一个选择宏内核而不是微内核的理由是性能。
测量性能的指标:吞吐量 throughput、延迟 latency。 提升性能的通用手段:批处理 batching、缓存 caching、并发 concurrency、调度 scheduling
会在后续的网络章节继续讲延迟与吞吐的话题。6.033 重点在于讨论系统设计中「通用的提升性能手段」,而不是如复杂度优化这一类场景相关的具体优化手段。
总结
在 Operating System 的 Lecture 结束后,已经理解了系统中单台机器上的模块化以及工作。后续讨论多机系统中机器之间互相交流必不可少的部分:网络。