源自于业务上遇到的一个先将某个语句Prepare再Execute查询效率很低的问题,而将查询中的参数直接嵌入到SQL语句内并以文本形式执行,则执行反而变得很快。
测试环境:腾讯云 MySQL 服务(txsql8.0.22)、MySQL 源码编译(refs/tags/mysql-8.0.22)
问题描述
背景
MySQL 中,语句执行有两种方式,分别是 Text Protocol 和 Prepared Statement。两者主要的差别是传参方式的不同(返回包格式也不同,这里不展开)。
- Text Protocol 是直接将语句中的参数嵌入到 SQL 语句中,以文本的形式整个语句直接传递到数据库。(后面称为「文本SQL模式」)
- Prepared Statement 则是先 COM_STMT_PREPARE 一个查询语句的模板,如
SELECT * FROM t1 WHERE a = ? AND b = ?,然后再执行 COM_STMT_EXECUTE,将实际的参数传入,替换掉占位符?并执行。(后面称为「Prepare/Execute模式」)
问题
定位并简化问题查询,得到最小可复现样例:
表结构:
1
2
3
4
5
CREATE TABLE t1 (
col1 BIGINT NOT NULL,
KEY idx_t1_col1(col1)
);
查询:
1
SELECT * FROM t1 WHERE col1=10036 ORDER BY col1 ASC LIMIT 5;
可以看到,这个查询限定结果集中 col1 = 10036,然后要求结果按照 col1 排序实际上 ORDER BY col1 ASC 是冗余的,因为结果中所有的 col1 的值都是一样的(10036)。
问题在于:这个查询,在表数据量较大(200w)时,Prepare/Execute模式下的速度非常慢(~100ms),而文本SQL模式则很快(0.7ms)。
这个是比较反直觉的,因为 Prepare/Execute模式的优势之一就是传递数据更高效,并且可以避免重复解析语句,每次执行只需要插入参数(Prepared_statement::insert_params())并优化即可执行,理论上应该比文本SQL模式更快。
相比之下
SELECT * FROM t1 ORDER BY col1 ASC LIMIT 5(删掉Where,只保留 Order By)只要0.7ms,也就是 Where 和 Order By 同时存在的时候,同一个语句,Prepare/Execute模式的性能出现了明显降低,而文本SQL模式不受影响。
问题分析
由于执行的是同一个语句,排除了两种模式的RTT差异因素后,初步怀疑是「Prepare/Execute模式」和「文本SQL模式」下,优化器生成的执行计划出现了差异导致。
使用 SET SESSION OPTIMIZER_TRACE='enabled=on';,打开 optimizer trace,分别以prepare/execute和文本SQL形式执行该SQL,得到优化器 trace:
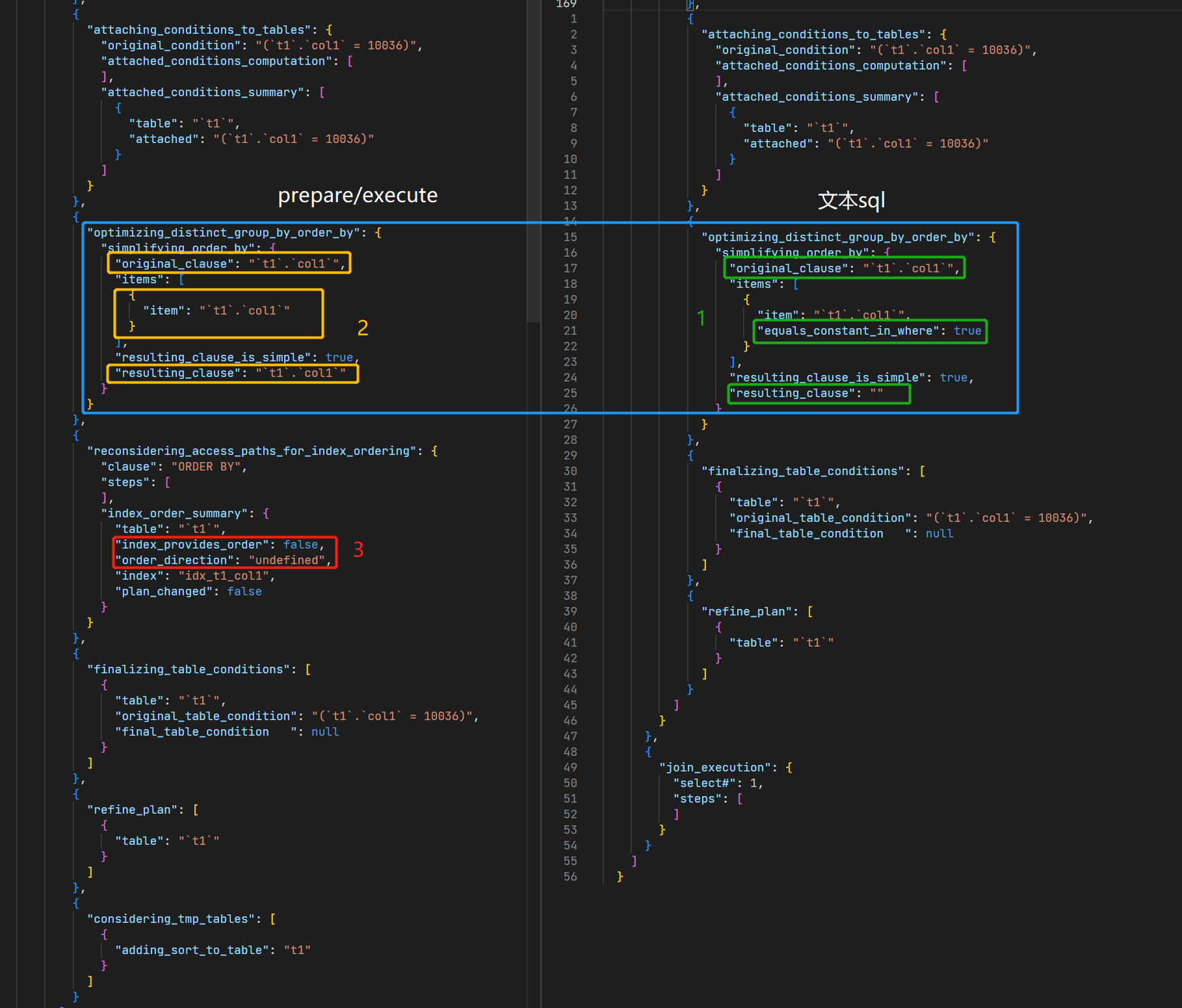
可以看到 trace 中大多数优化流程和结果是完全一致的(符合预期,因为毕竟是同一个语句),但是在 optimizing_distinct_group_by_order_by ,即 ORDER BY 优化部分出现了差异。
问题1 Prepare/Execute模式没有剔除冗余 ORDER BY
前面提到在我们制定的查询条件 col1 = 10036 下,ORDER BY col1 ASC 实际上是冗余的,因为 col1 是常量,理论上该阶段优化器会剔除掉这个 ORDER BY。
- 文本SQL模式执行时,优化器成功地发现了这一点(图中1),即
"equals_constant_in_where": true,并正确地将该冗余 order by clause 优化掉,resulting_clause为空。 - Prepare/Execute模式下,优化器由于某些原因,并没有发现 col1 实际上恒等于一个常量,没有在这一阶段优化掉冗余的 order by(图中2)
(最后结论是为 MySQL 8.22 的一个 bug)
问题2 ORDER BY 没有利用索引
但是这不是效率低的全部原因,因为即使优化器没有剔除掉冗余 ORDER BY,由于 col1 上有索引,对 col1 的 ORDER BY 也应该是不会产生排序操作的,理论上可以直接访问索引得到有序 col1,相比直接剔除 ORDER BY 也不应该会慢这么多(百倍)。
这里继续往下可以看到,Prepare/Execute模式下,优化器出于某种原因,在考虑 order by 的执行路径的时候,认为 col1 上的索引(KEY idx_t1_col1(col1))无法满足我们要进行的排序条件("index_provides_order": false)(图中3),这显然是错误的,导致了执行器不从索引上直接获得有序的 col1,而是自己又对所有数据进行了一次排序,导致效率低下。
这里注意到 order_direction 为 undefined,在 MySQL 8.0.22 源码上验证,没有成功复现,原版 MySQL 中 trace 出来的这个 key 的 order_direction 为 asc,并且能够正确使用索引来避免对 col1 进行排序。
原因调查
问题1 冗余 ORDER BY 剔除
源码编译 mysql 8.0.22,并挂载 gdb,由于 optimizer trace 中体现出来的差异是 equals_constant_in_where (where条件等于常量)是否为 true,全局搜索这个关键字,发现是在 JOIN 语句优化部分的 JOIN::remove_const 函数中,该函数被 JOIN::optimize_distinct_group_order 函数调用,即这部分逻辑是在判断 ORDER BY 中是否存在按常量列排序的 clause,如果存在则剔除掉(符合预期)。
部分调用栈
1
2
3
4
5
6
7
8
9
10
11
12
13
#0 const_expression_in_where at sql/sql_select.cc:3798
#1 JOIN::remove_const at sql/sql_optimizer.cc:9865
#2 JOIN::optimize_distinct_group_order at sql/sql_optimizer.cc:1261
#3 JOIN::optimize at sql/sql_optimizer.cc:614
#4 SELECT_LEX::optimize at sql/sql_select.cc:1905
#5 SELECT_LEX_UNIT::optimize at sql/sql_union.cc:680
#6 Sql_cmd_dml::execute_inner at sql/sql_select.cc:924
#7 Sql_cmd_dml::execute at sql/sql_select.cc:725
#8 mysql_execute_command at sql/sql_parse.cc:4344
#9 Prepared_statement::execute at sql/sql_prepare.cc:3487
#10 Prepared_statement::execute_loop at sql/sql_prepare.cc:2994
#11 mysqld_stmt_execute at sql/sql_prepare.cc:1891
# ......
JOIN::remove_const() 函数
优化器JOIN语句优化阶段,移除常量的 order by 或 group by 条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
// sql/sql_optimizer.cc:9774
ORDER *JOIN::remove_const(ORDER *first_order, Item *cond, bool change_list,
bool *simple_order, bool group_by) {
// ......
// line 9812
// 对于每一个 order_by 条件
for (order = first_order; order; order = order->next) {
Opt_trace_object trace_one_item(trace);
trace_one_item.add("item", order->item[0]);
table_map order_tables = order->item[0]->used_tables();
if (/* ......aggregation检查 */)
// ......
else if (/* ......子查询优化 */) {
// ......
} else if (/* ......重复排序检查 */) {
// ......
} else if (/* ......检测子查询 */)
// ......
else { // line 9861
if (order_tables & (RAND_TABLE_BIT | OUTER_REF_TABLE_BIT))
*simple_order = false;
else {
// !!检查排序的依据列是否是常数值,即所有行这一列的值都相等
if (cond && const_expression_in_where(cond, order->item[0])) {
trace_one_item.add("equals_constant_in_where", true);
continue; // 如果是,则跳过,忽略该 ORDER BY
}
if ((ref = order_tables & (not_const_tables ^ first_table))) {
// ......
}
}
}
if (change_list) *prev_ptr = order; // use this entry
prev_ptr = &order->next;
}
// ......
return first_order;
}
这里调用了 const_expression_in_where(cond, order->item[0]) 函数,来判断 cond (也就是 WHERE 中指定的筛选条件)中是否有使得排序条件 order->item[0] 恒等于某个值的条件,从而决定是否剔除 ORDER BY order->item[0] 的排序条件 (比如 col1 = 10036 这样的条件)
const_expression_in_where() 函数
8.0.24 后叫 check_field_is_const()
判断 WHERE 条件 cond 内是否有能使得结果集中 comp_item 恒为某个常数的条件。 如果有,则可以断言 ORDER BY comp_item 为冗余操作,可以剔除。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// sql/sql_select.cc:3773
bool const_expression_in_where(Item *cond, Item *comp_item,
const Field *comp_field, Item **const_item) {
// ......
if (cond->type() == Item::COND_ITEM) {
// `a = ?` 这样的条件实际上是一个布尔比较函数,所以不是走到这个分支
// ......
} else if (cond->eq_cmp_result() != Item::COND_OK) { // 布尔比较函数
Item_func *func = (Item_func *)cond;
if (func->functype() != Item_func::EQUAL_FUNC &&
func->functype() != Item_func::EQ_FUNC)
return false;
// 如果是等于比较(left = right)
Item *left_item = ((Item_func *)cond)->arguments()[0];
Item *right_item = ((Item_func *)cond)->arguments()[1];
// 且 left 或 right 其中有一个是要检查的目标 comp_item
// 则检查 `left = right` 这个条件是否足够保证 comp_item 的值的唯一性
if (equal(left_item, comp_item, comp_field)) {
if (test_if_equality_guarantees_uniqueness(left_item, right_item)) {
if (*const_item) return right_item->eq(*const_item, true);
*const_item = right_item;
return true;
}
} else if (equal(right_item, comp_item, comp_field)) {
if (test_if_equality_guarantees_uniqueness(right_item, left_item)) {
if (*const_item) return left_item->eq(*const_item, true);
*const_item = left_item;
return true;
}
}
}
return false;
}
原理是对于每一个 WHERE col = xxx 的条件,检查 col = xxx 条件成立能否保证 col 在结果集中的值唯一(test_if_equality_guarantees_uniqueness),这里需要检查:
- 右侧的量
xxx是否是个常量(不能是引用其他的列,也不能是一个子查询) - 是否类型一致,如果是字符串,编码是否一致
注(与主问题无关):仅仅满足
xxx是常量并不足以保证结果集中的col的值唯一,因为在col的类型和xxx不一致的时候,会出现 type cast 自动类型转换。 比如当col的类型是 string,而xxx是个 int 的时候,可能会出现如下情况:
mysql> insert into t2 values("123"),("123a"),("123bbbc"); Query OK, 3 rows affected (0.01 sec) mysql> select * from t2 where col = 123; +---------+ | col | +---------+ | 123 | | 123a | | 123bbbc | +---------+ 3 rows in set (0.03 sec)这是由于 col 的值在和 123 做比较的时候,会将两者都 typecast 成 double,然后再进行比较,string cast 到 double 的时候,会丢弃掉尾部无效字符,
123bbbc会只剩下123,导致"123bbbc" = 123结果为 true。 这里的条件col = 123就是一个等号右侧为常量,但是还是无法保证结果集中该列的「值唯一」的例子。 https://dev.mysql.com/doc/refman/8.0/en/type-conversion.html
test_if_equality_guarantees_uniqueness() 函数
8.0.24 后叫 check_field_is_const() 检查 「
l = r条件成立」能否推出「结果集中l的值唯一」
需要检查:
r是否是个常量(r->const_item()是否为 true)- 是否类型一致,如果是字符串,编码是否一致
1
2
3
4
5
6
7
8
9
10
11
12
// sql/sql_select.cc:3730
static bool test_if_equality_guarantees_uniqueness(const Item *l,
const Item *r) {
return r->const_item() &&
/* elements must be compared as dates */
(Arg_comparator::can_compare_as_dates(l, r) ||
/* or of the same result type */
(r->result_type() == l->result_type() &&
/* and must have the same collation if compared as strings */
(l->result_type() != STRING_RESULT ||
l->collation.collation == r->collation.collation)));
}
这里检查「r 是否是个常量」的方法是 r->const_item(),继续跟踪发现,这个方法判断的是 r 在整个 Prepared_statement 中是否恒定为常量。
Item::const_item() 函数
该 item 是否是个常量(要求在整个表达式中自始至终都是常量,不管执行状态如何)
这里是问题所在。
回到一开始的例子中:
1
SELECT * FROM t1 WHERE col1 = 10036 ORDER BY col1 ASC LIMIT 5;
Prepare/Execute 模式
这个查询中的条件 col1 = 10036,Prepare/Execute模式下,在优化器眼里其实是 col1 = ?,使用 gdb 打出 left_item 和 right_item 可以验证这一点: 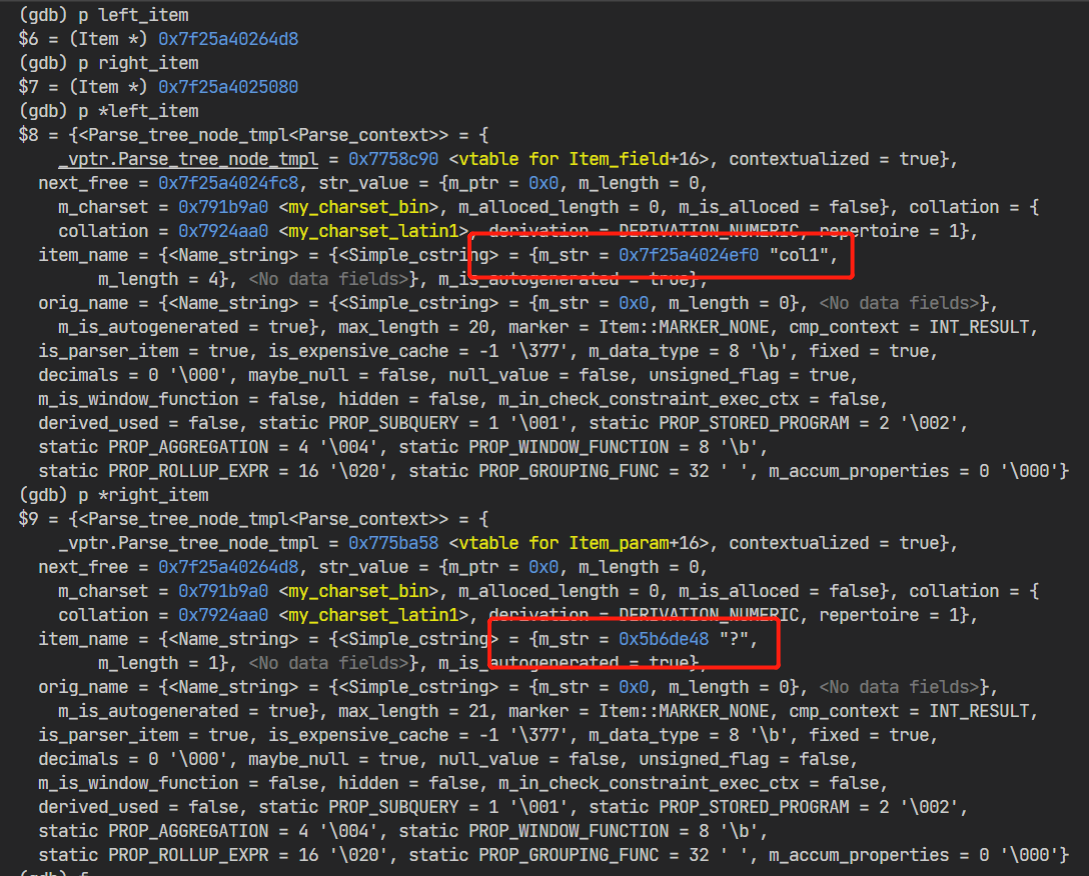
而占位符 ?,由于实际的值需要 execute 阶段才传入,prepare 阶段自然是不把它标记为常量的。
占位符对于这个表达式本身来说也的确不算常量(理由是每一次 execute 传入的实际值可能都不一样),最多只能说它在「某一次具体的执行过程」之中,才可以被认为是常量:
1
2
3
4
5
6
7
8
(gdb) p left_item->item_name.m_str # 左 item 名称(col1)
$76 = 0x7f25a4024ef0 "col1"
(gdb) p right_item->item_name.m_str # 右 item 名称(?)
$77 = 0x5b6de48 "?"
(gdb) p ((Item_param*)right_item)->value.integer # 右 item 代入值
$78 = 10036
(gdb) p right_item->const_item() # 右 item 在表达式中是否恒为常量
$79 = false
即对于 col1 = 10036 条件,在 Prepare/Execute 模式下,实际上优化器看到的是 col1 = ? ,right_item->const_item() 会返回 false。这一点在 Item::const_item() 中也有提到:
1
2
3
4
5
6
7
8
9
10
/**
Returns true if item is constant, regardless of query evaluation state.
An expression is constant if it:
- refers no tables.
- refers no subqueries that refers any tables.
- refers no non-deterministic functions.
- refers no statement parameters. -- 即 `?`
- contains no group expression under rollup
*/
bool const_item() const { return (used_tables() == 0); }
从而导致 test_if_equality_guarantees_uniqueness() 认为结果集中 col1 的值可能不唯一,所以认为需要保留(实际上是冗余的)ORDER BY col1 条件。
文本SQL模式
相比之下,如果我们用文本SQL方式执行,即 col1 = 10036,则这个条件的右参数 10036 在表达式解析 Prepare 的时候,值就已经确定下来了,所以 right_item->const_item() 为 true:
1
2
3
4
5
6
(gdb) p left_item->item_name.m_str # 左 item 名称(col1)
$80 = 0x7f25a4024de0 "col1"
(gdb) p right_item->item_name.m_str # 右 item 名称(10036)
$81 = 0x7f25900074b0 "10036"
(gdb) p right_item->const_item() # 右 item 在表达式中是否恒为常量
$82 = true
所以该模式下 col1 = 10036 能够通过 test_if_equality_guarantees_uniqueness 检查,优化器能够剔除掉冗余的 ORDER BY col1。
从而出现了同一个语句在「Prepare/Execute 模式」和「文本SQL模式」下产生了不同的执行计划的现象。
分析 & 结论
test_if_equality_guarantees_uniqueness() 要做的,实际上是检查【在这次执行中】 某个 WHERE 条件能否确保结果集中的某一列唯一。所以其检查的第一个条件 r->const_item()(参数是否在整个表达式构造的时候就是 constant 的,无论执行状态)实际上是 overkill。
(因为 Prepare/Execute 模式下每一次 Execute 都会用当次传入的参数重新跑一遍 optimize) 对于优化器来说,判断某个占位符 item 是否为常量,实际上并不需要关心这一次 Execute 的时候这个占位符的值是不是永远和之前每一次 Execute 的时候相同(即r->const_item()为 true),而只需要知道【同一次 Execute 过程内】该占位符 item 的值是常量就足够了。
Item类实际上也提供了一个方法用来判断某个 item 是不是同一次 execution 内是常量,这个就包括了 ? 占位符的情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
/**
Returns true if item is constant during one query execution.
If const_for_execution() is true but const_item() is false, value is
not available before tables have been locked and parameters have been
assigned values. This applies to
- statement parameters <---重点
- non-dependent subqueries
- deterministic stored functions that contain SQL code.
For items where the default implementation of used_tables() and
const_item() are effective, const_item() will always return true.
*/
bool const_for_execution() const {
return !(used_tables() & ~INNER_TABLE_BIT);
}
使用 gdb 验证,col1 = ? 中的参数?(代入参数值10036):
1
2
3
4
5
6
7
8
(gdb) p right_item->item_name.m_str # item 名称
$77 = 0x5b6de48 "?"
(gdb) p ((Item_param*)right_item)->value.integer # 代入值
$78 = 10036
(gdb) p right_item->const_item() # 在表达式中是否恒为常量
$79 = false
(gdb) p right_item->const_for_execution() # 在*某次具体执行*中是否是常量
$80 = true
解决方法就是用 const_for_execution() 替换 test_if_equality_guarantees_uniqueness() 中的 const_item() 判断:
1
2
3
4
5
6
7
8
9
10
11
static bool test_if_equality_guarantees_uniqueness(const Item *l,
const Item *r) {
return /* r->const_item() is overkill */ r->const_for_execution() &&
/* elements must be compared as dates */
(Arg_comparator::can_compare_as_dates(l, r) ||
/* or of the same result type */
(r->result_type() == l->result_type() &&
/* and must have the same collation if compared as strings */
(l->result_type() != STRING_RESULT ||
l->collation.collation == r->collation.collation)));
}
幸运(不幸)的是,追踪代码库中这一行的提交历史,可以看到,这个 bug 在 mysql-8.0.24 中已经被修复了,修复方法就是使用 const_for_execution() 替换 const_item(),具体的 patch 是 443384454fdbb365a20bfbf86f552ab914d1ea92。
changelog:
Filesort was used for a query having an ORDER BY … DESC clause, even when an index on the descending column was available and used. This happened because an ORDER BY sub-clause was not removed due to matching a field in an equality predicate, even though it should have, so that the optimizer did not match the query with the descending index, leading to suboptimal performance. (Bug #101220, Bug #32038406)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
The problem here is that an ORDER BY sub-clause was not removed
due to matching a field in an equality predicate, even though it should.
Because of this, the optimizer fails to match the query with a
descending index, causing non-optimal performance.
The essence of the problem is that the function
test_if_equality_guarantees_uniqueness() returns false if collation of
left and right hand side of equality predicate are different.
However, this should not make a difference as long as the collation of
the column in the index matches the collation of the equality operation.
And these should be the same since they are both derived from the
collation of the column.
Thus, the main part of this bugfix is to pass down the actual operation
to the function, and perform an improved collation check.
The logic of the function was also further enhanced:
- It now accepts const values and const-for-execution values such
as user variables and dynamic parameters.
- It is more specific on rejected predicates involving temporals and
strings (it rejects predicates where the column is a string and the
const value is a temporal).
Regression tests were added for these changes as well.
经过验证这个 bug 在 mysql-8.0.22 到 mysql-8.0.23 中存在 。腾讯云线上使用的是基于 mysql-8.0.22 的修改版本,所以存在这个缺陷。
edit: 了解到这个 bug 是在 mysql 8.0.22 官方实现 prepare once 功能时引入的众多 bug 之一: https://dev.mysql.com/worklog/task/?id=9384
总结(TLDR)
这个问题总结起来就是:优化器在优化 ORDER BY col1 的时候,有一个检查「WHERE 条件是否使得结果集中 col1 的值唯一」的检查,作用是如果有存在 WHERE col1 = 10036 这样的条件,则意味着结果中所有 col1 的值都会是 10036,那 ORDER BY col1 排序与否就没有任何差别了,可以直接优化掉。
这个检查的其中一个步骤,是检查 col1 = xxx 后面的 xxx 部分是不是一个常量,因为如果假设条件是 col1 = RAND() 之类,就不能保证结果集中 col1 的值还是唯一的了。
问题在于,这个检查在 Prepare/Execute 模式下,MySQL检查过严了,将 col1 = ? 中的占位符 ? 认为不满足常量条件,不是一个常量,从而导致没能剔除冗余的 ORDER BY col1,使得执行计划非最优。
而文本模式下, col1 = 10036 中的 10036 是满足常量检查条件的,所以优化器成功剔除了冗余的 ORDER BY,产生了比 Prepare/Execute 模式更高效的执行计划。
问题2 ORDER BY 没有利用索引
问题1解释了为何 「Prepare/Execute 模式」下产生的执行计划会比「文本SQL模式」多一个排序的步骤,但是这并不能完整解释为何性能会差那么多,[[#问题分析]]中提到了,Prepare/Execute 模式下,不仅多出来了 ORDER BY 步骤,而且这个步骤本该能利用 col1 上的索引的,但是实际上并没有使用索引,而是进行了一次外排。
由于这个问题在 MySQL 8.0.22 上没能复现,认定为可能是 TXSQL 8.0.22 的问题,由于没有 TXSQL 8.0.22 的源码,联系内核的维护者协助调查。(WIP)
解决方案
对于项目中遇到的场景,在指定 WHERE col1 = xxx 条件的时候,在构造SQL时就不添加 ORDER BY col1 条件,防止触发bug。
并且选择用文本SQL模式来执行请求,规避潜在的问题。